Zookeeper数据是以文件形式存储在硬盘上的,以snapshot为主,txnlog为辅。因为当对内存数据进行变更的时候,会保证将事务操作记入log日志,而snapshot只是内存某一个时刻影像,为了性能takeSnapshot生成snapshot并不是实时的,而是由后台线程根据一定规则处理的
来看看snapshot和txnlog在磁盘上的文件
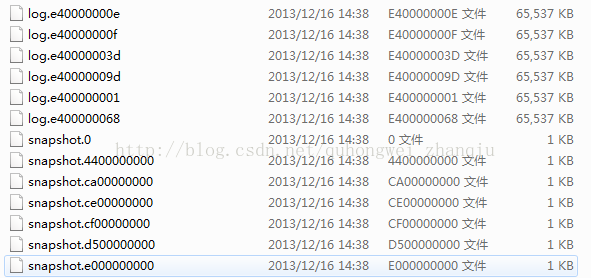
文件名是以log.或者snapshot.加上一串long的16进制数字组成,这个long值就是zxid服务器端事务id
Snapshot文件名生成, FileTxnSnapLog.save方法中
long lastZxid = dataTree.lastProcessedZxid;
FilesnapshotFile = new File(snapDir, Util.makeSnapshotName(lastZxid));
如上代码创建一个新的snapshot文件,工具Util用来用来创建文件名
public static String makeSnapshotName(long zxid) {
return "snapshot." +Long.toHexString(zxid);
}
日志Log文件生成,在FileTxnLog.apend方法中,如果被执行了rollLog方法,那么文件输入流会被清空,这里会创建一个新的文件
if (logStream==null) {
logFileWrite = new File(logDir,("log." + Long.toHexString(hdr.getZxid())));
fos = newFileOutputStream(logFileWrite);
………
}
如上代码可以看出文件名是最新请求的zxid,这里snapshot和log文件都和zxid有关,那么下面我们来看看zxid。
Zxid
当客户端一个事务请求操作是leader的PrepRequestProcessor处理器会对请求进行预处理包括生成zxid设置到请求中去,zxid的生成是通过调用ZookeeperServer.getNextZxid生成
protected long hzxid = 0;
synchronized long getNextZxid() {
return ++hzxid;
}
它是hzxid一个自增的long值,有没有奇怪这个变量取名叫做hzixd多了一个h, h我的理解是high的缩写代表64位long的高32位。Zxid的分为两部分高32位用来存储每次选举的时代epoch,低32位用来存储事务请求的自增序列。所谓选举时代就是一个数值,标记代表一次选举,跟年份一样是自增的。每次服务器启动或者zookeeper异常导致重新选举都会在原来epoch值加一代表一个新的时代,工具类ZxidUtils用来操作前32或者后32位
public class ZxidUtils {
static public long getEpochFromZxid(long zxid) {
return zxid >> 32L;
}
static public long getCounterFromZxid(long zxid) {
return zxid & 0xffffffffL;
}
static public long makeZxid(long epoch,long counter) {
return (epoch << 32L) | (counter & 0xffffffffL);
}
static public String zxidToString(long zxid) {
return Long.toHexString(zxid);
}
}
比如现在epoch=4代表经历了4次选举,如果重新选举后epoch值为5,通过工具类的zxid=hzxid=ZxidUtils.makeZxid(5,0)= 21474836480,此时低32重新开始值为0, 如果这时来了新的请求值为zxid=21474836481=21474836480+ 1 = ZxidUtils.makeZxid(5, 1)
评论