QuorumPeer的run方法中主要用来进行选举,以及选举后进入各角色,角色被打破重新再进行选举,下图大体流程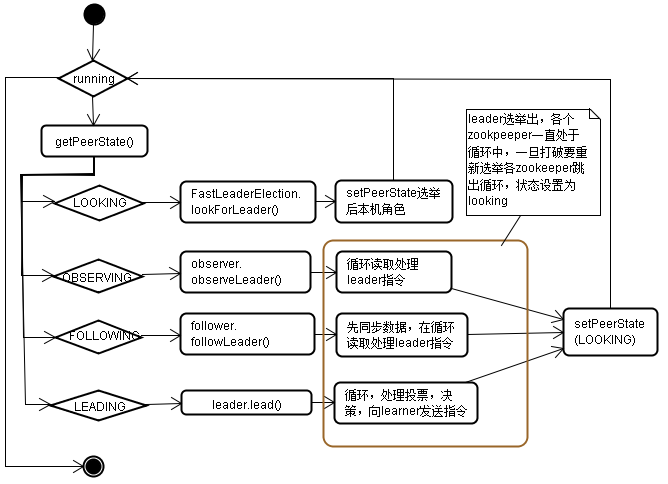
2.1.1基本概念
Logicalclock, currentEpoch,acceptedEpoch epoch zxid
2.2.2选举算法创建
Zookeeper启动的时候,quorumPeer线程的start方法的调用startLeaderElection方法来创建选举算法, 创建过程如下:
1) 选举算法的创建之前先创建QuorumCnxManager,QuorumCnxManager利用tcp协议来进行leader选举,每一对server之间都会保持一个tcp链接,每个zookeeper会打开一个tcp/ipj监听集群中的其他server。
1.1) receiveConnection(socket)方法用来建立连接
1.1.1) 读取请求连接zookeeperserver的sid(myid)
1.1.2) 对方sid小于自己sid, 立马关闭连接, 自己做为client向对方请求建立连接, 注意zookeeper 服务之间都是配置myid大的作为客户端连接myid小的作为服务器端。
1.1.3) 对方sid大于自己sid, 创建server端的发送线程任务和接收线程任务,并且启动任务准备发送和接收client端数据
1.2) connectOne(sid):本zookeeper作为客户端向sid(myid)的zookeeper发起链接请求
1.2.1) 向对方zookeeper写入本机sid
1.2.2) 对方sid大于本机, 关闭socket链接,注意zookeeper服务之间都是配置myid大的作为客户端连接myid小的作为服务器端。
1.2.3) 对方sid小于本机,创建client端的发送线程任务和接收线程任务,并且启动任务准备发送和接收server端数据
1.3) SendWorker: 如同其名字run方法从阻塞的发送队列中取数据发送
1.4) RecvWorker: 如同其名字run方法将接收到数据放入阻塞队列中,供FastLeaderElection. WorkerReceiver线程任务消费
2) QuorumCnxManager.listener.start()
Listener线程任务, 绑定地址开启ServerSocket服务,用来侦听其他server连接,进行集体间选举,投票, 数据同步。Server链接数有限,是基于bio的长连接。
Socketclient = serverSocket.accept();
receiveConnection(client);//处理建立连接请求
3) FastLeaderElection:创建选举对象
3.1) 构建发送队列LinkedBlockingQueue
3.2) 构建接收队列LinekdBlockingQueue
3.2) 创建消息处理对象Messenger, 它有WorkerReceiver和WorkerSender两个线程子类型对象组成, 这个两个线程对象的作用就如它的名字一样
3.2.1) WorkerReceiver
3.2.2) WorkerSender
2.2.3选举流程:
1) Logicalclock++
2) 初始化提案:
2.1)建议选举的leader自己proposedLeader=myid
2.2)proposedZxid=lastLoggedZxid datatree中记录的最后事务id
2.3)proposedEpoch=currentEpoch 当前本地文件currentEpoch中存储的值 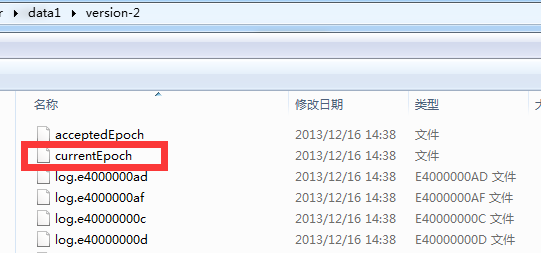
3) 向其他服务发送通知消息:
遍历集群中的所有的server, 构建选举建议提案
ToSend notmsg = newToSend(ToSend.mType.notification,
proposedLeader,
proposedZxid,
logicalclock,
QuorumPeer.ServerState.LOOKING,
sid,
proposedEpoch);
将消息加入到发送队列中。
4) LOOKING状态循环:
4.1)从接受队列中获取消息n
4.2) n为空
4.2.1) 发送队列为空,遍历集群中的所有的server, 构建选举建议提案加入发送队列
4.2.1)发送队列不为空, connectAll 查看所有服务如果没有建立连接建立。
4.3) n不为空, 判断服务状态
4.3.1) LOOKING: 接收的投票还没有选举出leader
4.3.1.1)若n.electionEpoch>logicalclock
接受到消息的选举时代大于本机计算器,更新本地logicalclock,
清空收到的投票集合,
然后将收到的消息n跟自己比较判断采用哪种提案,判断规则如下:相等的情况看下一条
newEpoch > curEpoch
newZxid > curZxid
newId > curId
更新选举提案
向其他server发送选举提案消息,先加入发送队列异步发送
4.3.1.2) n.electionEpoch< logicalclock 对方选举时代过期,废弃,break重新循环
4.3.1.3) n.electionEpoch== logicalclock 决策提案规则如下相等情况看下一条
newEpoch > curEpoch
newZxid> curZxid
newId > curId
如果采用对方提案, 更新本机提案并向其他server发送选举提案消息,先加入发送队列异步发送
4.3.1.4) 将对方提案构建成投票对象vote,保存到接收投票集合, 到这里本机的提案信息应该是最新的了
4.3.1.5) termPredicate(recvset,new Vote(proposedLeader, proposedZxid, logicalLock, proposedEpoch)) 将接收到的提案跟自己的提案比较,大于一般set.size()>集群数/2
如果没有大于一半,跳出本次循环
如果大于一半,从接收队列取消息, 如果有消息判断投票提案有没有更新有更新将消息加入接收集合, 如果接收队列中没有新的消息那么根据最新投票设置本机角色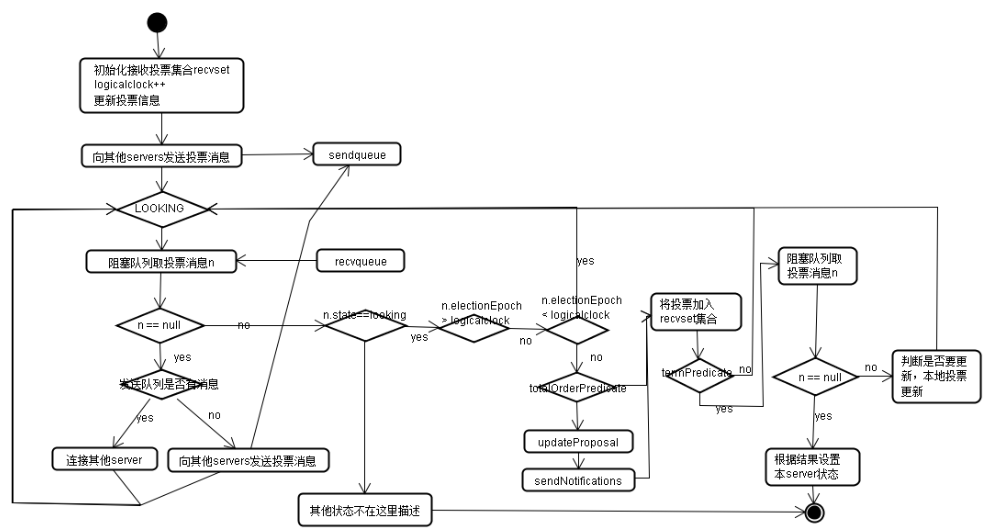
4.3.2) OBSERVING:
选举过程,OBSERVING不参与,只打印debug日志
4.3.3) FOLLOWING 或者 LEADING
接收的投票信息已经有leader选举出了
4.3.3.1) n.electionEpoch== logicalclock 接收到消息选出了leader跟本机是在一个选举时代
将消息加入接收的投票集合recvset
判断recvset集合中是不是多数投个n消息指定的leader
将消息加入一个外部选举的集合outofelection用来存放外部选举出leader的消息
判断大多数outofelection集合中的follower是否跟随同一个leader
2.2 OBSERVING 本机是观察者
2.2.1)建立跟leader server的socket链接
2.2.2) 向leader server注册本oberser服务, 注册过程除了向leader表明本server的角色外, 还会将自己的acceptedEpoch提交给leader, leader判断更新再向自己反馈最新的acceptedEpoch
2.2.3)从leader同步数据
2.2.4)启动while循环,接收leader指令
PING: 接收心跳消息, 并将自己持有的session作为心跳内容返回
PROPOSAL,COMMIT,UPTODATE: 记录日志,不做操作
SYNC:观察者同步数据
REVALIDATE: 重新建立session
INFORM: 观察者通过这种消息类型来提交数据, (对于follower要先PROPOSAL在COMMIT)
2.3 FOLLOWING 本机处于跟随者状态
2.3.1)建立跟leader server的socket链接
2.3.2)向leaderserver注册本follower服务,注册过程除了向leader表明本server的角色外,还会将自己的acceptedEpoch提交给leader, leader判断更新再向自己反馈最新的acceptedEpoch
2.3.3) 做一次检查leader返回的epoch小于本机accpetedEpoch绝不应该出现的
2.3.4)从leader同步数据
2.3.5)启动while循环,接收leader指令
PING:接收心跳消息, 并将自己持有的session作为心跳内容返回
PROPOSAL:leader向follower提交了一个变动操作提案
COMMIT: leader向follower确认变动操作
UPTODATE: follower启动后不应该接受到这个操作
REVALIDATE: 重新建立session
SYNC: 同步数据
2.4 LEADING 本机处于领导状态
一但选举出leader如果本机就是leader,那么Quorumpeer.run进入LEADING分支进行作为leader角色的初始化及进入leader角色的工作,由Leader.lead()执行,下面我们来看看执行流程:
2.4.1) loadData加载数据, zookeeperServer利用snapshot和txtLog恢复数据加载到内存
2.4.2) 获取leader的epoch,lastProcessedZxid
2.4.3) 构建LearnerCnxAcceptor线程任务并启动
LearnerCnxAcceptor用来侦听集群中的learner(follower&observer),并跟它们建立连接,leader跟每个learner的连接都会构建LearnerHandler线程任务来跟learner一对一单独交流
2.4.4) 获取最新接收的选举时代epoch
这个是通过接收所有(这里也不是所有,是通过策略,默认大于一般, 否则阻塞等待)zookeeper集群的lastAcceptedEpoch比较出最大一个在加一得出,
2.4.5)根据最新epoch创建新的zxid,高32位是epoch,低32位是id计数
2.4.6) 构建leader, epoch信息的对象QuorumPacket,向集群中的learner发送, learner接收后epoch大于自己acceptedEpoch的更新learner的acceptedEpoch
将自己加入newLeaderProposal.ackSet集合
然后接收各个learner反馈(默认大于一半否则会阻塞等待)
设置currentEpoch,序列化到本地文件
2.4.7) leader通过learnerhandler与各个learner进行交互,在leader向各个learner发送newLeaderProposal后,各个learner反馈后, 各个learner就会根据最新的epoch,zxid来跟leader进行数据同步,同步完成后会向leader发送ack消息,leader接收到后将ack消息加入到newLeaderProposal.ackSet, 所以leader的下一步操作就是循环判断newLeaderProposal.ackSet个数是否超过一半
2.4.8) 启动while循环用来定时向learner发送心跳, 同时决策集群中活着的server是否大于一半, 如果不是退出循环会重新在选举
评论